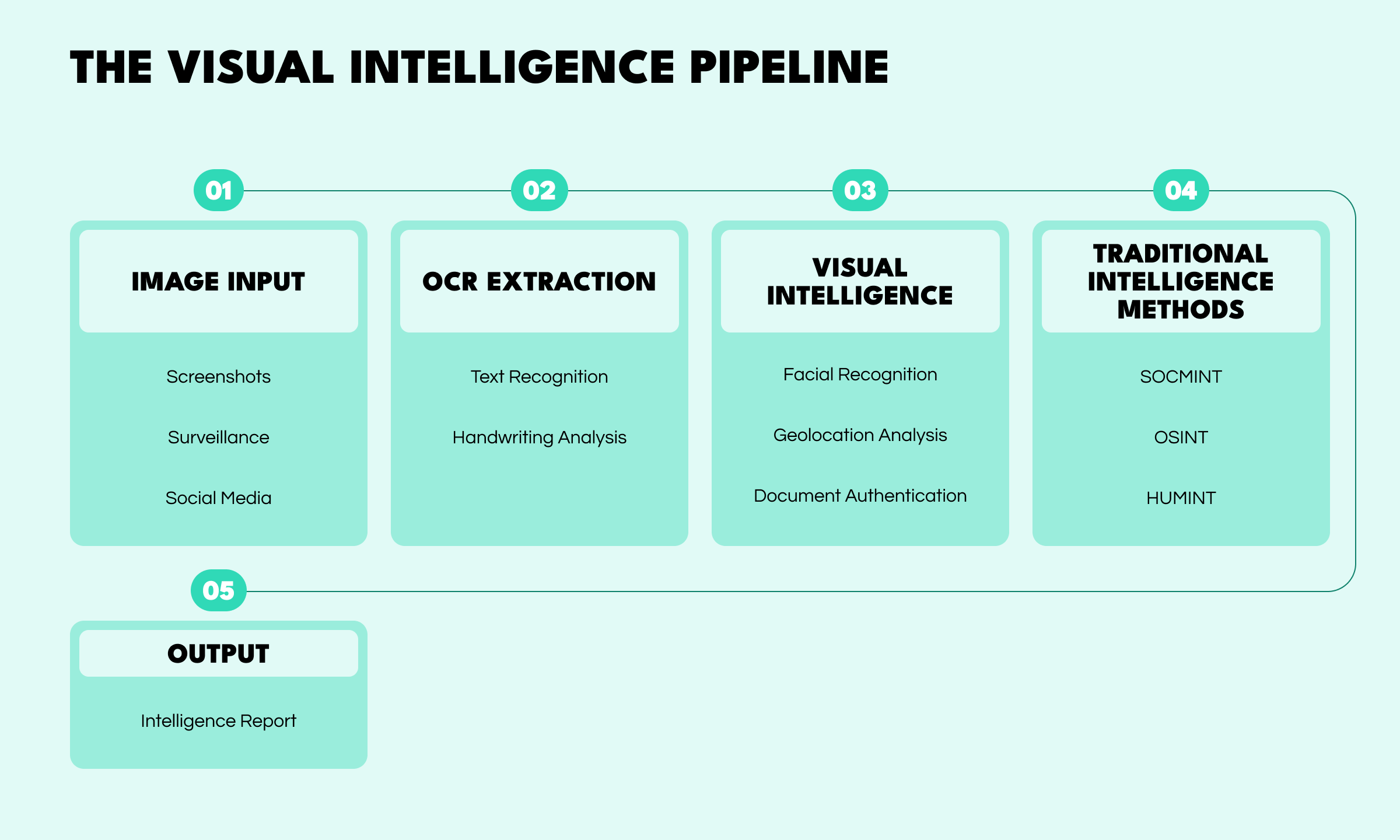
From Image to Intelligence: OCR and Computer Vision

With so much of the world’s information living inside images—screenshots of messages, photos of documents, surveillance clips, and even social media posts with hidden location data—Optical Character Recognition (OCR) and computer vision have become cornerstones of modern intelligence work. And with the AI renaissance, the laborious manual tasks of the past can now be done in minutes, uncovering patterns and connections that the human eye alone might miss.
This article looks at how these technologies are transforming the OSINT toolkit: automating text extraction, analyzing visual data at scale, and seamlessly integrating with traditional intelligence workflows. We’ll also explore how the rise of multimodal AI systems is reshaping the future of visual analysis, where machines don’t just read images but understand them.
OCR is one of the most powerful tools in visual intelligence. It converts text locked inside images into searchable, editable data, turning screenshots, scanned documents, or surveillance stills into something analysts can actually work with. What once required hours of manual review can now be done in seconds, revealing names, phrases, or patterns that might otherwise go unnoticed.
Text recognition is the core of OCR. It allows analysts to pull written information from almost any image source. A blurry photo of a document that once seemed useless? OCR can extract every word. A screenshot shared in a private chat becomes searchable, indexable, and linkable to other pieces of evidence. Even license plates caught in surveillance footage can be automatically read and organized through computer vision.
Handwriting recognition takes things a step further. It teaches machines to understand human writing—even messy, inconsistent script—and convert it into usable text. This capability is especially valuable in forensic work, archival research, or document-heavy investigations, where handwritten notes or forms may contain key details.
Tools for OCR and handwriting analysis range from simple open-source libraries to enterprise-grade systems:
The real trick is picking the right tool for the job—social media investigations need fast, bulk processing while forensic analysis depends on precision and audit trails, and document analysis calls for metadata extraction and structure retention. With the right setup, OCR turns noise into intelligence, giving analysts a clearer picture of the data hiding in plain sight.
While OCR focuses on text, computer vision takes things further by enabling machines to interpret and analyze the visual world much like a human would, identifying faces, objects, landmarks, and subtle patterns that even skilled analysts might overlook amid large, complex datasets.
By analyzing facial features across images and video, these systems can locate and connect individuals across social media, surveillance footage, and open web sources. Although privacy laws restrict their use in many cases, they remain an essential part of legitimate intelligence workflows, helping analysts confirm identities, detect impersonation, and uncover digital connections that might otherwise go unnoticed.
Every photo contains environmental clues: a street sign, a building style, a mountain ridge, or even the angle of sunlight. Geolocation tools use these details to match visuals with real-world coordinates. When analyzed properly, such context can verify where an image was taken, track movements, or corroborate field reports with surprising precision.
In an era of synthetic media and deepfakes, verifying the authenticity of visual materials is more important than ever. Image-forensic tools analyze lighting, texture, and metadata to detect edits or manipulations. Whether it’s identifying a forged signature or exposing a composite image, these methods help ensure that what appears real actually is—a cornerstone of credible intelligence work.
Computer vision and OCR don’t replace traditional intelligence work, they enhance it. When combined with established methods, they help analysts move faster, verify information, and see connections that might otherwise stay hidden.
Online platforms are a goldmine of visual information. By combining OCR and computer vision, analysts can extract text from screenshots, identify objects like weapons or vehicles, and even geolocate images based on background scenery. These techniques help uncover hidden links between users, track disinformation campaigns, or connect digital identities across different accounts.
Large-scale investigations often involve vast collections of scanned documents, archived news articles, or image-heavy databases. OCR makes this data searchable, transforming static files into structured intelligence. What used to take days of manual reading can now be automated, letting researchers focus on patterns and relationships instead of transcription.
Visual verification strengthens human-sourced information. A simple photo can confirm a report, validate a source’s claim, or expose inconsistencies that hint at deception. Facial recognition tools can help verify identities, while metadata and image analysis can reveal when or where a photo was really taken. In practice, this means stronger vetting, fewer false leads, and a clearer picture of reality.
Every tool that processes data leaves a footprint. When using OCR and computer vision for investigative or intelligence work, understanding how and where that data is handled is crucial. A single oversight in operational security can expose sensitive sources, leak information, or compromise an entire case.
Cloud-based OCR services are fast and powerful, but they log requests and often store processed data. For sensitive investigations, local or on-premises processing is the safer choice—it keeps content under your control and reduces the risk of leaving traces on third-party servers.
Free online tools might seem convenient, but many retain uploaded files or metadata for “service improvement”. That means your investigation data could end up in someone else’s database. Enterprise-grade solutions offer better privacy controls, but contracts and integrations can still reveal patterns of activity or investigative intent if not handled carefully.
Different regions have different laws around data collection and image processing. What’s legal in one country may violate privacy or surveillance laws in another. Some major platforms, like Meta, explicitly prohibit the creation of facial recognition databases using their imagery. Violating such policies can lead to legal issues and long-term reputational damage.
Creating an effective visual intelligence setup isn’t just about collecting tools—it’s about finding the right balance between speed, accuracy, and security. Every choice you make, from where your data is processed to how results are verified, affects both reliability and safety.
Online OCR platforms are fast, convenient, and often easy to use, but that convenience comes at a cost. When you upload images to a third-party service, you lose control over where your data goes and how it’s stored. For sensitive work, locally installed or on-premises tools provide more security and full ownership of your data, though they require more setup and maintenance.
When investigations scale up, automation becomes essential. Batch processing tools can handle hundreds of social media profiles or hours of surveillance footage at once. Open-source options like Tesseract can be scripted for bulk operations, while enterprise platforms offer intuitive interfaces and collaborative workflows that save valuable time.
Modern OCR tools now handle a wide range of scripts—from Arabic and Chinese to Cyrillic and beyond—and can even process mixed-language documents automatically. This multilingual flexibility is crucial for global investigations where intelligence rarely comes in just one language.
Even with advanced tools, challenges remain. Poor image quality, low resolution, or bad lighting can reduce accuracy. Data overload is another constant issue; large-scale investigations can generate terabytes of images, and without automation, critical details may go unnoticed. And while AI can extract and categorize data quickly, false positives still happen, meaning human verification remains indispensable.
The next big leap in visual intelligence is already unfolding. OCR and computer vision are now merging with Multimodal Large Language Models (MLLMs)—systems that can read, interpret, and even reason around text and images at once. Instead of just extracting data, these models understand it in context.
Next-generation models like GPT-4V, Qwen2-VL, and LLaVA-1.5, along with specialized APIs such as Mistral OCR, can now analyze documents, tables, and images in a single pass. They don’t just recognize text; they understand what that text means and how it fits within the surrounding visuals. For example, they can distinguish a legal contract from a medical report, interpret handwritten notes alongside typed annotations, and even infer document intent.
Much of this progress comes from transformer-based architectures like TrOCR, which process entire documents as connected structures rather than isolated text blocks. These systems can track relationships across pages, linking a signature on page three to a name mentioned on page one. Combined with self-supervised learning and synthetic data generation, they now require fewer labeled samples while achieving higher accuracy and adaptability.
As always, new capabilities come with tradeoffs. These advanced models demand significant computing power, and most are cloud-based, raising familiar questions about privacy, data control, and jurisdiction. For sensitive intelligence work, the focus is shifting toward secure, on-premises implementations that preserve the power of AI while maintaining strict data confidentiality.
The future of visual intelligence isn’t just about seeing more; it’s about understanding what we see. As OCR, computer vision, and AI continue to merge, the gap between human insight and machine perception grows smaller. The result is a new kind of analysis that doesn’t just process pixels but interprets the world behind them.
OCR and computer vision have completely reshaped how analysts collect, verify, and interpret information hidden in images. What once was an arduous and long-winded manual process now takes minutes, turning photos, documents, and videos into structured, searchable intelligence.
These tools don’t just extract data; they reveal patterns, confirm identities, and authenticate what’s real in a world flooded with manipulated media. When paired with sound methodology and human judgment, they transform visual information into reliable, actionable insight.
The next generation of intelligence systems won’t just read what’s in front of them—they’ll understand it. As technology continues to evolve, the challenge for analysts isn’t keeping up with machines but learning how to think with them, transforming pixels into context and context into truth.
Optical Character Recognition (OCR) converts text from images into searchable, editable data. In intelligence workflows, this means analysts can instantly extract text from photos, screenshots, or scanned files, turning visuals into usable information for further analysis.
While OCR focuses on text, computer vision interprets everything else—objects, faces, locations, and visual patterns. Together, they allow investigators to read, classify, and understand the full scope of information hidden within images or video footage.
That depends on where and how data is processed. Cloud-based tools often log and store user data, while local or on-premises solutions provide greater control and confidentiality. For high-sensitivity work, on-device or private infrastructure is strongly recommended.
Common challenges include poor image quality, language diversity, and data volume. Low-resolution images reduce accuracy, and multilingual content requires specialized models. Automated tools help process large datasets, but human validation remains essential for accuracy.
Next-generation systems like GPT-4V and TrOCR go beyond reading—they understand. These models process text and images together, recognizing context, structure, and intent. They represent the future of visual intelligence, where analysis becomes faster, deeper, and more accurate.
Want to see how integrated OSINT tools can transform the way you collect and analyze visual intelligence? Book a personalized demo with one of our specialists and explore how Crimewall streamlines OCR, computer vision, and data visualization, all within a unified investigative platform.






