Incident Response: What Containment Misses

Incident response is no longer just about stopping threats. The hard part today is not just containing an attack quickly. It is understanding what happened well enough to stop the same kind of attack from working again, improve detection, and learn from the attacker faster than they can adapt. Teams that only focus on containment may close the immediate incident, but they often miss the bigger lesson. Teams that learn from every incident steadily get better at defending the environment.
In this article, we look at what incident response actually involves, how containment differs from understanding, which tools and methods matter most, and how intelligence-driven approaches help turn reactive response into something more durable.
Incident response is the structured way organizations detect, investigate, and respond to security incidents before the damage spreads.
In practice, that means handling unauthorized access, malware infections, data breaches, insider misuse, phishing attacks, and fraud-related activity across multiple systems at once. Depending on the incident, teams may rely on detection tools, forensic analysis, threat intelligence, case management, or broader investigation workflows.
The job is not just to stop the immediate threat. It is also to understand what happened, determine the scope of impact, preserve evidence when needed, and support remediation that reduces the chance of the same problem happening again.
Organizations operate in environments where threats are constant and changing. Without effective incident response, even small issues can turn into serious breaches.
Good response reduces attacker dwell time, limits operational and financial damage, preserves evidence when legal or regulatory questions arise, and helps security teams improve over time by feeding lessons back into detection and prevention.
But there is a real difference between stopping an incident and learning from it. Containment deals with the immediate problem. Understanding helps prevent the next one. Strong programs do both.
Not every incident response program is trying to achieve the same outcome.
Containment is about stopping the immediate threat. Compromised accounts are disabled. Infected systems are isolated. Malicious processes are killed. Access is blocked. The priority is speed.
Understanding is about figuring out what really happened. How did the attacker get in? What else did they touch? What did the team miss the first time around? What does this incident reveal about weak spots in detection, visibility, or response?
Containment focuses on stopping the damage now. Understanding focuses on explaining what happened and reducing the chance of it happening again.
That shift matters. Once teams stop treating incidents as one-off emergencies and start using them to improve how they detect, investigate, and respond next time, the whole function becomes more useful. That means preserving evidence before destroying it, correlating activity across systems and timeframes, using threat intelligence to see whether the incident fits a known pattern, and reviewing the incident afterward in a way that actually changes something.
It also changes how success is measured. A containment-focused team closes incidents quickly. A team that is trying to learn looks at whether the incident made the organization harder to hit next time.
The incident response process exists to bring structure into moments that are usually messy and time-sensitive. It works as a continuous cycle where each incident helps improve how teams handle the next one.
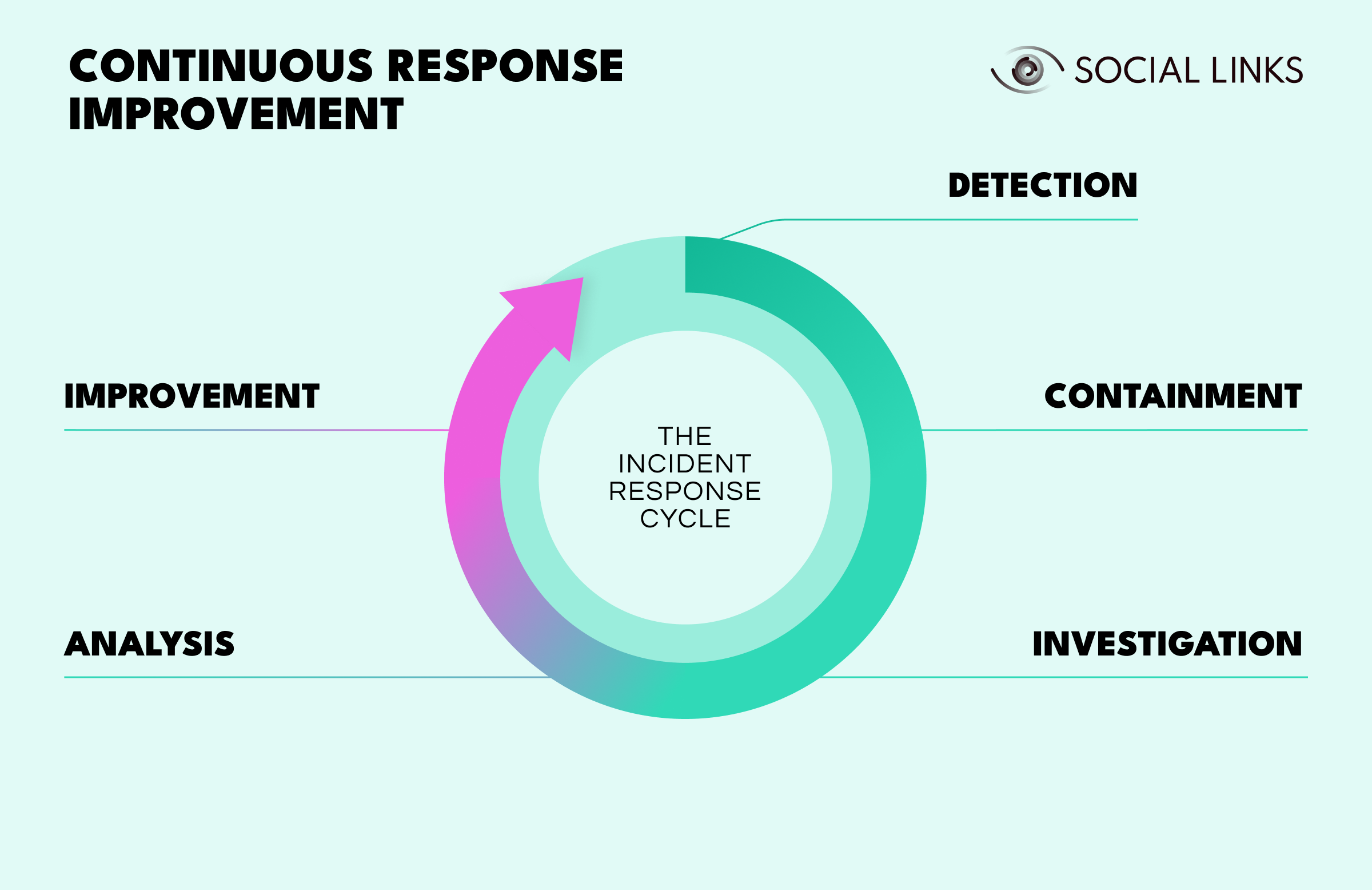
Detection is where response begins. Something suspicious shows up through an alert, a monitoring system, a user report, or outside intelligence.
Containment follows quickly. Systems are isolated, accounts are disabled, traffic is blocked, or malicious processes are stopped. The urgency is real because every minute can give an attacker more time to spread, steal data, or establish persistence.
Investigation determines what actually happened. Teams trace how the attacker got in, what systems were affected, what data was accessed, and whether the threat has been fully contained.
Analysis makes sense of the findings. Teams work out whether this incident fits a known pattern, what the team missed initially, how detection could improve, and what this reveals about gaps in security.
Improvement closes the loop. Teams update detection rules, strengthen controls, refine response procedures, and document lessons learned. This is where the value of the incident gets captured—not just in stopping this threat, but in making the organization harder to hit next time.
The cycle then repeats. Better detection from one incident leads to faster containment in the next. Investigation findings improve analysis. Analysis insights drive improvement. And those improvements feed back into stronger detection.
Many organizations treat incidents as finished once the immediate threat is gone. Strong programs recognize that the real value comes from using each incident to strengthen the entire cycle.
One of the hardest parts of incident response is that the fastest way to stop an incident is often the fastest way to destroy the evidence needed to understand it.
A compromised system gets isolated and reimaged. The malware is gone, but so is the chance to understand how it got there, what it did, where it spread, or whether it left persistence behind somewhere else. An account gets disabled immediately. The unauthorized access stops, but investigators lose visibility into what the attacker touched, what they downloaded, or whether other accounts were also involved.
This tension is real. Containment prioritizes speed, yet an investigation needs evidence. In fast-moving incidents, teams rarely get to do both perfectly.
The better programs plan for that. They build workflows that preserve critical evidence before aggressive containment begins. Memory is captured before systems are powered down. Logs are preserved before accounts are reset. Network activity is recorded before connections are blocked. Evidence preservation becomes part of response, not something teams remember afterward.
Even then, collecting evidence is only part of the work. Many teams save the data and never really analyze it. The incident gets closed, but the organization never fully understands what happened.
Detection tells you that something suspicious may be happening. Analysis tells you whether it matters.
Modern detection pulls from many places: endpoint alerts, unusual network traffic, suspicious logins, phishing detections, cloud activity, and user-reported anomalies. The problem is not producing alerts. Most environments produce far too many of them.
The harder part is figuring out which alerts represent real threats and which ones are noise.
That takes correlation across systems, timeline building, an understanding of attacker behavior, and enough evidence preservation to keep the picture intact while the team works. This is where many response functions struggle. The tools flag everything. The analysts still have to decide what deserves immediate attention.
Effective response depends on using several tools together rather than expecting one platform to do everything.
SIEM systems aggregate logs and correlate events across the environment.
EDR tools give teams endpoint visibility, containment options, and forensic data.
Network monitoring tools help identify lateral movement, suspicious traffic, and exfiltration behavior.
Forensic platforms preserve evidence, recover artifacts, and help reconstruct attacker activity.
Case management systems keep investigations organized and findings documented.
These tools matter, but they do not explain incidents on their own. A SIEM can correlate authentication activity, but it cannot tell you whether it reflects normal behavior or stolen credentials. EDR can isolate an endpoint, but it cannot explain how the malware arrived or whether it already spread elsewhere. Teams still have to interpret what the tools are showing them.
Intelligence-driven incident response changes the way teams look at incidents. Instead of treating each one as a separate emergency, they start asking whether the activity fits something they have seen before.
Has this infrastructure appeared in earlier incidents? Are there related indicators elsewhere in the environment? Does the behavior match a known campaign or attacker technique? What does external intelligence say about the threat?
That approach adds pattern recognition across incidents, enrichment from threat intelligence, proactive hunting based on indicators discovered during investigations, and feedback loops that improve future detection and response.
The result is not just a faster response team. It is a response function that gets smarter over time.
Internal logs show what happened inside the environment. OSINT helps explain what may be happening outside it.
When investigators find suspicious domains, IP addresses, email accounts, wallets, or infrastructure during incident response, open-source intelligence can help connect those indicators to a wider pattern. A domain in your logs may link to dozens of others in the same campaign. An email address may show up in prior breach data, reporting, or earlier attacks. Infrastructure choices may line up with known attacker habits.
OSINT helps with infrastructure mapping, attribution support, digital footprint analysis, and identifying related entities or activity that internal systems cannot see on their own.
This matters most in phishing, fraud, and cyber attack investigations, where outside context often determines whether the incident was opportunistic, targeted, isolated, or part of something larger.
Even mature programs run into the same problems.
Evidence disappears quickly. Logs expire, memory is volatile, systems change, and attacker infrastructure goes offline. Teams often have minutes, not hours, to capture what they need.
Data is fragmented. Useful evidence sits across endpoints, cloud systems, identity platforms, network devices, and third-party services that do not fit together cleanly.
Alert volume overwhelms teams. Modern environments generate more signals than most analysts can review carefully in real time.
Attribution is uncertain. Figuring out who is behind an attack takes time, correlation, and outside context. Rushing that process creates false confidence.
And speed always fights with thoroughness. Containment pushes for immediate action. Investigation needs care and evidence preservation. Balancing both under pressure is where many response programs struggle.
This is why incident response cannot rely on automation alone. Tools help teams move quickly. Human judgment is what turns that speed into understanding.
Improving incident response is less about buying more tools and more about building workflows that balance speed with learning.
Effective programs have clear response plans before incidents happen. They preserve evidence before containment wipes it out. They correlate activity across systems and timeframes instead of treating each alert in isolation. They bring in threat intelligence and OSINT where outside context matters. They document findings consistently so one incident improves the response to the next. And they actually review incidents after the fact in a way that changes detection, response, or prevention.
The goal is not perfection. It is responding consistently and learning enough to do better next time.
Modern incident response often depends on context that internal systems cannot provide on their own, including infrastructure relationships, adversary patterns, entity connections, and outside intelligence that helps explain what an indicator actually means.
Social Links helps response teams analyze digital footprints, map infrastructure and relationships, connect internal indicators to outside entities and known threats, and support OSINT investigations when those external connections affect response decisions.
This is especially useful in phishing, fraud, and cybercrime investigations where knowing who is behind the activity, what infrastructure they control, and whether it fits a known campaign changes how a team responds.
Incident response is not just about stopping threats. It is also about learning from them quickly enough to stop the next one.
Organizations that focus only on containment may close incidents fast, but they miss the chance to improve. Teams that investigate thoroughly, use intelligence well, and carry lessons forward get better over time.
The best response programs combine speed with depth, containment with investigation, and reactive work with deliberate learning. That is what separates teams that only put out fires from teams that steadily reduce risk.
Incident response detects, investigates, and responds to security threats before damage spreads. It combines immediate containment with investigation, recovery, and review.
The process works as a continuous cycle: detection identifies threats, containment stops immediate damage, investigation determines what happened, analysis uncovers patterns and gaps, and improvement feeds lessons back into better detection and response. Each incident strengthens the next.
Containment stops the immediate threat. Understanding explains how the attack worked, what else was affected, and how to prevent something similar from succeeding again.
OSINT adds outside context. It helps investigators understand infrastructure, identify related activity, validate indicators, and determine whether an incident is isolated or part of a broader campaign.
Evidence disappears quickly, data is fragmented, alert volumes are high, attribution is uncertain, and speed often conflicts with careful investigation. A good response means balancing all of that under pressure.
Want to see how external intelligence supports incident response? Book a personalized demo and discover how SL Crimewall helps response teams connect internal indicators to outside infrastructure, validate threat intelligence, and understand adversary patterns through integrated OSINT workflows.






