It’s a facet of the digital age, an exponentially expanding market, and an essential discipline spanning various sectors, but what exactly is OSINT?
Answering this seemingly simple question is not actually that straightforward. And with a lot of people having different questions concerning the topic, we wanted to devote a whole article to clearly laying out what we see as the most fundamental qualities of open-source intelligence.
Thanks to our own experience and research we’ve been able to compile a shortlist of burning questions that the uninitiated audience tend to most commonly ask, and which we dutifully address in a Q&A format below. From the OSINT tools and techniques involved, to the wide array of possible applications, we’ll be discussing it all.
So, if you’d like to get a firm grasp on the topic, read on.
To start at the beginning, OSINT is an acronym standing for ‘open-source intelligence’ – a term which can be misleading at first glance. When people see ‘open-source,’ they most commonly associate it with software whose code can be freely modified. In the case of open-source intelligence however, it actually means ‘derived from the public domain.’ Additionally, the word ‘intelligence’ isn’t limited to materials of secretive government bureaus but more generally refers to ‘applied information.’
A little history. OSINT was born during WWII when the US government began amassing intelligence on their adversaries through closely studying newspapers, magazines, radio broadcasts, photos and other public media, in an attempt to discern enemy strategies and objectives. This practice was referred to as Research and Analysis, and the department which carried out such operations formed a branch of the Office of Strategic Services (OSS) – later to be known as the CIA.
In the advent of the internet and the colossal rise of social media, OSINT took on a new meaning and nature. The sheer profusion of open data that became available for analysis transformed open-source intelligence from a little-known reconnaissance method into a full-blown international industry with diverse uses across the public and private sectors.
So, what is OSINT? In a nutshell, it is the process of extracting and analyzing public information to generate actionable intelligence for a range of applications.
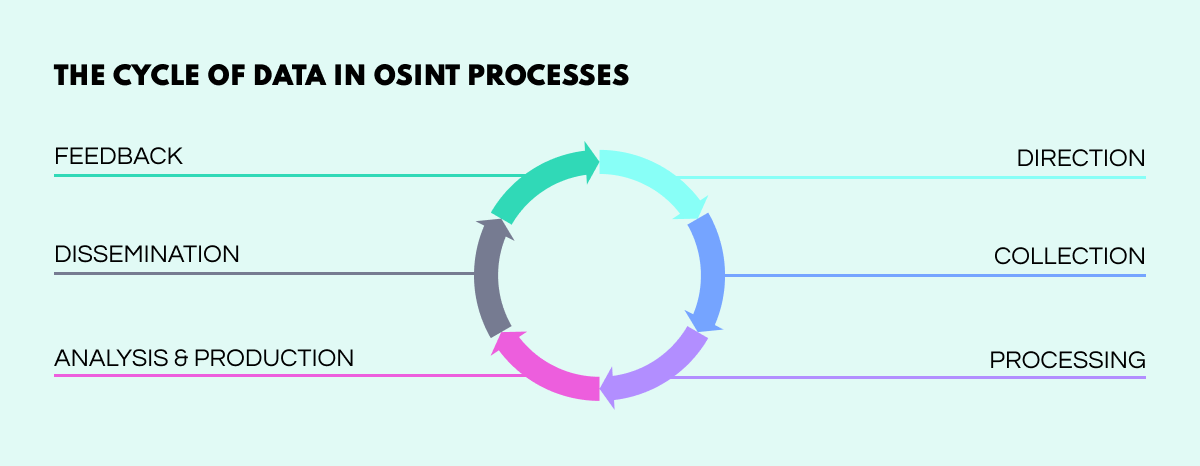
The various stages behind the production of open-source intelligence
Is OSINT Legal?
In a word, yes. But the question arises naturally enough. With many aspects of OSINT involving a form of surveillance, the chief concern centers around privacy: Is it really ok to collect information around an individual or a group based on their personal online activity?
The reason the answer is ‘yes’ goes back to the nature of the information, which is, by definition, in the public domain and legally accessible to all. Most people in the twenty-first century must be aware that the internet is not a private place. This is especially the case with social media which almost revolves around the idea of disseminating your personal life to the public.
The data which OSINT analysts look at is already available to everyone. An objection against the public availability of your data can arguably be leveled against social media policies, but you can also argue that the real responsibility lies with the individuals who elect to broadcast their lives via such platforms.
Who Uses OSINT?
It’s difficult to imagine a category of organization where OSINT frameworks couldn’t be put to some productive use, however some of the spheres where it has gained most traction include law enforcement, government, corporate and cyber security, as well as private investigation.
Law enforcement agencies (LEAs). With people living out so many aspects of their lives online, we have seen a decline in HUMINT (Human Intelligence) – inspectors plodding the streets, knocking on doors etc. – and a vast increase in OSINT. This is especially the case with criminal investigations ranging from trafficking to money laundering cases.
Governmental bodies. Military organizations use open data for conducting effective and reliable reconnaissance as well as counter espionage. Meanwhile, national security departments rely on open-source intelligence techniques to identify threat groups such as terror cells, maintain effective incident response to natural disasteres and riots, conduct sentiment analysis, combat misinformation, and other civil responsibilities.
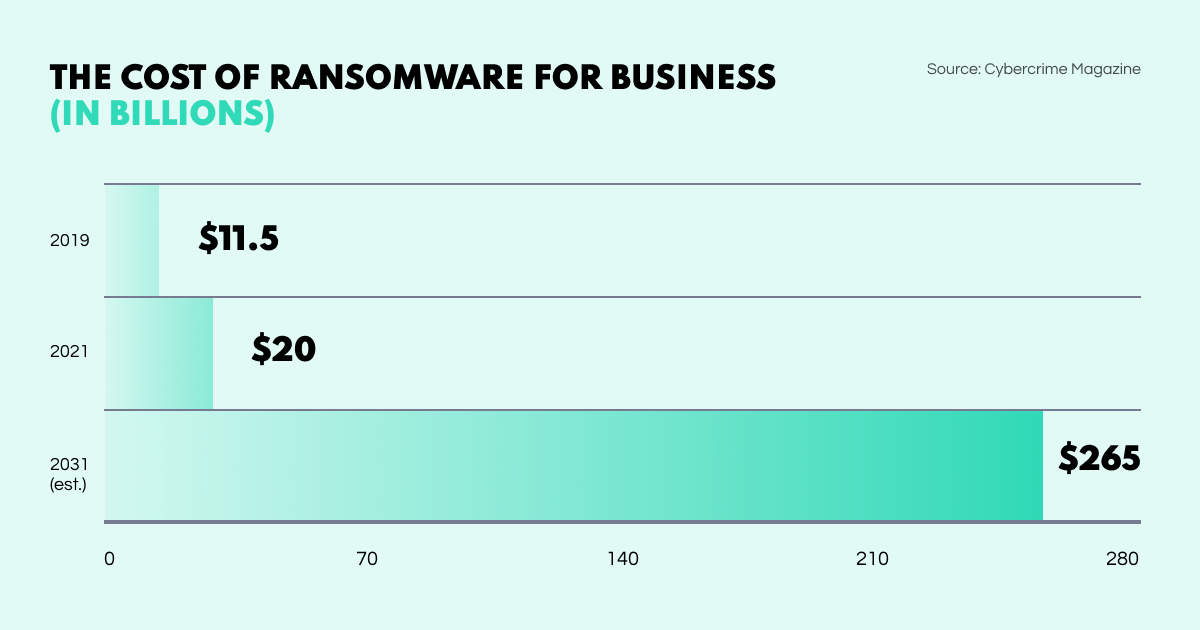
Corporate and cyber security. With businesses losing millions of dollars through single instances of ransomware attack or corporate data compromise, companies are paying greater attention to their information security. OSINT frameworks are a crucial part of threat intelligence including penetration testing and incident response, but can also be harnessed to mitigate perennial problems such as human error in social engineering scams or even sheer data carelessness.
Corporate losses through ransomware are ballooning
How Does OSINT Work?
OSINT approaches differ from case to case, but there are central techniques to generating actionable intelligence across both data gathering and analysis stages.
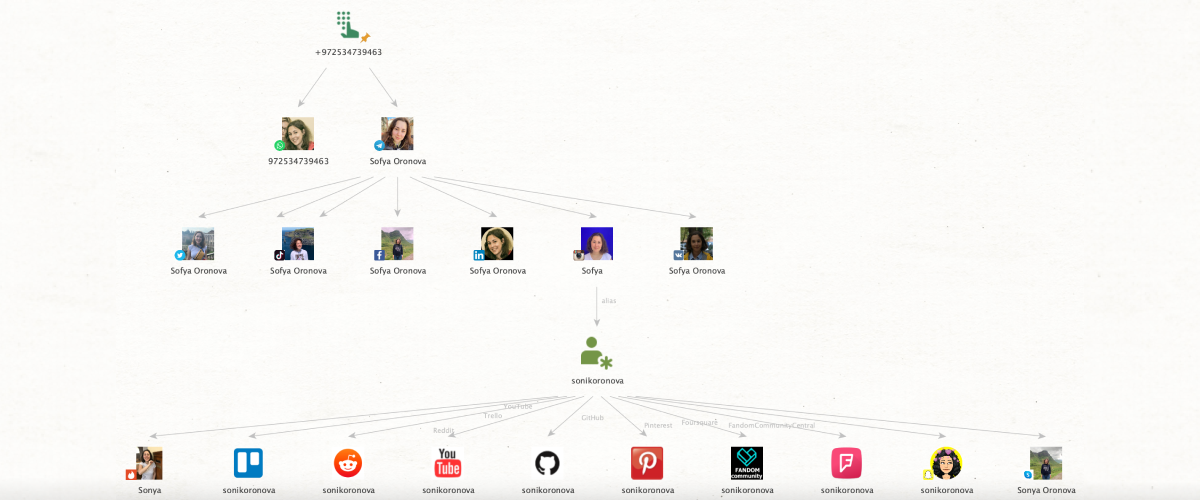
Digital Footprinting. The gathering process consists largely in scouring online sources such as social media to find and establish the activity of a given group or individual. As an investigator builds a picture of the subject’s online presence, this is referred to as a ‘digital footprint.’ These digital impressions of a subject’s online can be used to verify or falsify assertions or identities, as well embody evidence.
Example of a digital footprint
Link Analysis. Making sense of reams of open data is a formidable task for the OSINT analyst. To facilitate the process, visualization tools are used, helping the analysts to create a comprehensible picture from the extant data. By viewing data points as visual reference points on a graph, investigators can use vertices to piece together immense networks mapping out all the connections, affiliations, acquaintances, geolocations, subscriptions, etc. which are relevant to a particular investigation. From this vantage point, threat actors or questionable activities can be quickly traced and identified.
Object Detection. Analysts may also just want to scan the data sphere for a particular item to gain indicators about the threat posed by a given person or group. So, instead of elaborating a digital footprint around a given subject, investigators can home in on particular objects such as weapons or insignia to monitor the groups or individuals connected with the material. This can be highly effective in crime prevention as well as after-the-fact investigations.
How is OSINT used in Law Enforcement?
Modern criminal investigations are increasingly hinging on OSINT as a fundamental discipline to resolve various types of cases. Digital forensics, reconnaissance, and footprinting, are now central methods in the majority of modern investigative work, where LEAs and investigation bureaus increasingly depend on open data for verifying information, collecting evidence, and finding new leads across a range of inquiries:
Money Laundering. The wide-ranging adoption of cryptocurrencies – especially among the criminal classes – has added a crucial source to the open datasphere: the blockchain. While Bitcoin and other cryptos are largely considered anonymous, by applying OSINT technologies to explore blockchains intelligently, transactions can be linked to user addresses and assets can be traced to combat money laundering and mitigate financial risks.
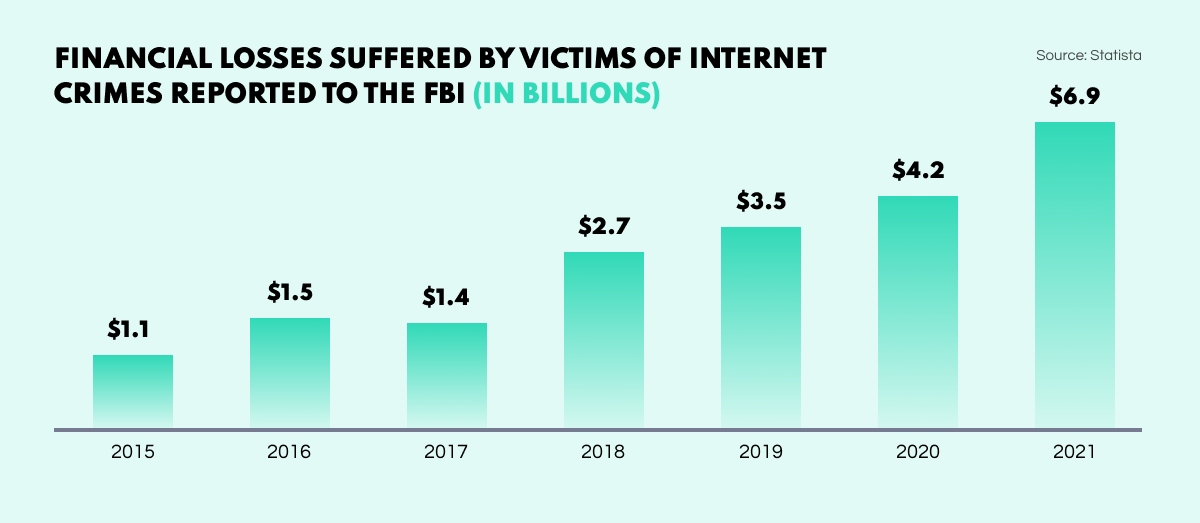
Fraud. According to a recent report by the FBI, 2021 was yet another record year for online fraud with losses amounting to $6.9 bln. Financial scams can take many forms but often involve social engineering. OSINT techniques are used to identify suspect emails and sock puppet accounts constructed for malicious purposes, and can home in on the real-world individuals behind the online personas.
The internet crime business is booming
Human and Arms Trafficking. OSINT has proved to be a very effective resource for identifying traffickers of various kinds as part of border control as well as internal investigation. Machine learning algorithms can quickly scan immense amounts of open data to unearth indicators of contraband such as weapons. Using blockchain analysis to trace transactions relating to trafficking can also be an effective approach. Furthermore, the amassing of weak indicators can raise an analyst’s awareness of suspicious activities or individuals.
Organized Crime. Criminal organizations make significant use of modern communication platforms including social media, messengers, as well as the Dark Web in conducting their operations. OSINT tools empower investigators to quickly map and analyze the make-up, structure, and activities of crime syndicates including affiliations, member profiles, financial transactions, and connections to illegal operations.
How is OSINT Used by Government and Military Organizations?
A range of government bodies including military organizations and intelligence bureaus rely on the up-to-date and vast nature of open data to inform critical decision-making and security measures.
Sentiment Analysis and Riot Control. Uprisings may seem to emerge spontaneously and unexpectedly, but in most cases there are a plethora of weak indicators surfacing online that can predict civil disorder through changes in public sentiment. The OSINT systems of today can automatically conduct sentiment analysis and monitor the situation in real time so authorities get prior warnings of unrest and their locales. Furthermore, OSINT technologies are frequently instrumental in identifying mob members in the wake of a riot.
Disaster Response. Natural disasters have a chaotic dynamic all of their own, so it’s difficult to formulate response protocols which are reliably effective across the board. Inaccurate or out-dated information can lead to ineffective responses that can cost lives. The earliest signs of natural disasters appear and evolve promptly online, meaning social media is often the most up-to-date resource available. OSINT tools can continually monitor events to keep relevant departments informed on breaking information and specific geolocations.
Counter-Extremism. The complex and nebulous threat posed by modern extremist and terrorist organizations is difficult to overestimate, and requires a host of techniques and technologies to effectively tackle. By bringing together and consolidating massive volumes of data from a wide range of sources, OSINT systems can define even weak interconnections between people and automatically elaborate possible group structures complete with hierarchies including ring-leader and lieutenants, down to on-the-ground operatives.
Misinformation Measures. COVID-19 has shown that misinformation can be highly detrimental on both private and national levels. Aside from malicious informational intrusion from abroad, fake news and misinformation may also be created and disseminated by internal citizens. With intelligent AI-based search methods, OSINT tools can trace a huge range of misinformation from its source to its multiple dissemination points, so that government agencies can root out propaganda from the online ocean and help people gain access to a more balanced informational landscape.
How is OSINT used in Cyber Security?
With IBM listing cyber security failure as one of the most formidable problems facing the world today, it’s a problem which needs to be taken seriously in both private and public sectors. Enter OSINT.
Threat Intelligence. Plugging the gaps in your security perimeter is of paramount importance. OSINT methods and tools are commonly used to flag up all kinds of breach surfaces across open platforms. For instance, an employee’s social media account publishing adverts would be a clear indication of compromised security, giving hackers access to a company’s critical assets by extension. Sweeps performed by open-source intelligence tools can quickly identify an array of such vulnerabilities.
Incident Response. IR is a procedure for ensuring that an organization can effectively respond to security breaches or cyberattacks as they arise. The process involves investigation, mitigation, and recovery from security breaches, as well as prevention for future incidents. By filtering open sources for most up-to-date data iterations, OSINT solutions allow security breaches to be accurately understood, greatly facilitating the challenge of containment, and informing ever more effective preventative measures.
Blockchain and Dark Web Monitoring. Threat actors often depend on the supposed anonymity provided by cryptocurrencies and the Dark Web. However, by using open-source intelligence tools to scrutinize the blockchains of Bitcoin, Etherium and other cryptos, transactions can be traced to wallets. These, in turn, can be connected to other identifiers that may appear on the Dark or even Surface Web – and it’s goodbye anonymity.
How is OSINT used in Corporate Security?
In the wake of the COVID pandemic, businessesreally began to realize just how vulnerable their data and resources are in the digital age. In response, OSINT has risen as one of the leading forces of the resistance.
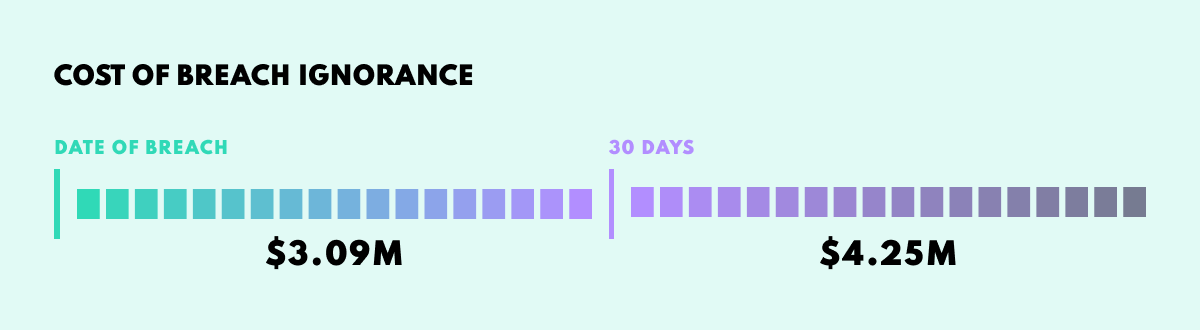
Data Leak Detection. Sadly, no system is totally immune to breaches. However, open data is a uniquely effective resource for finding evidence of a leak or security breach. Indications of data leaks appear online, but are often buried in the general flood of open data. OSINT tools can continually monitor sources across the datasp.here so that when a breach does occur, it is identified promptly. This can save companies millions of dollars, not to mention a huge amount of stress.
The quicker the containment, the more money is saved
Due Diligence and Background Checks. Knowing the risks associated with potential partnerships and contracts are clearly essential for doing businessin a secure and responsible way.Corporate security teams and HR units can leverage open data to carry out exhaustive assessments and profiling. Such background checks are crucial to accurately weigh up all risks connected to business deals, partnerships, and collaborations, as well as to individual job candidates. This not only preserves the company image, but substantial resources as well.
Social Engineering Countermeasures. Corporate security units often leverage open data to determine employee susceptibility to threat actors. By scanning employee accounts across social media and other services such as Outlook, Dropbox, etc, the subject’s activities can be checked for phishing content, and the employee can also be assessed for their capacity to deal with such threats.
Fraud and Corporate Theft. OSINT tools are often instrumental in finding the subtlest connections which uncover conflicts of interest and insurance schemes, saving organizations a lot of resources. Furthermore, instances of internal theft or ‘skimming off the top’ can be readily flagged up through the scanning open sources to compare internal figures with the broader indicators.
How Do OSINT Tools Help?
By definition, a tool should make your life easier. In the case of OSINT solutions, this is true in the extreme. So much so, that for modern analysts, getting through work without them is inconceivable.
Verification. How can you make good decisions if you’re basing them on erroneous information? In order to be trusted, sources require thorough verification from a range of data points. Since misinformation and propaganda is rife throughout the web, open data gatherers face a minefield of false or warped data that can mislead investigations. OSINT technologies allow data to be cross-checked through the comparison of multiple sources so analysts can gauge the reliability of the information they are working with.
Data Relevance. Information has a shelf life. The immense turnover of data pouring into the data sphere means that information can become out-of-date within a very short time-span. Consequently, a lot of data employed in cases has either ceased to be of relevance, or is actually erroneous. Modern open-source intelligence tools can collect and analyze information in real time, allowing subjects to be monitored and investigators kept entirely up-to-date. The investigative decision-making is consequently based on current, valid and relevant information, driving cases forward more effectively.
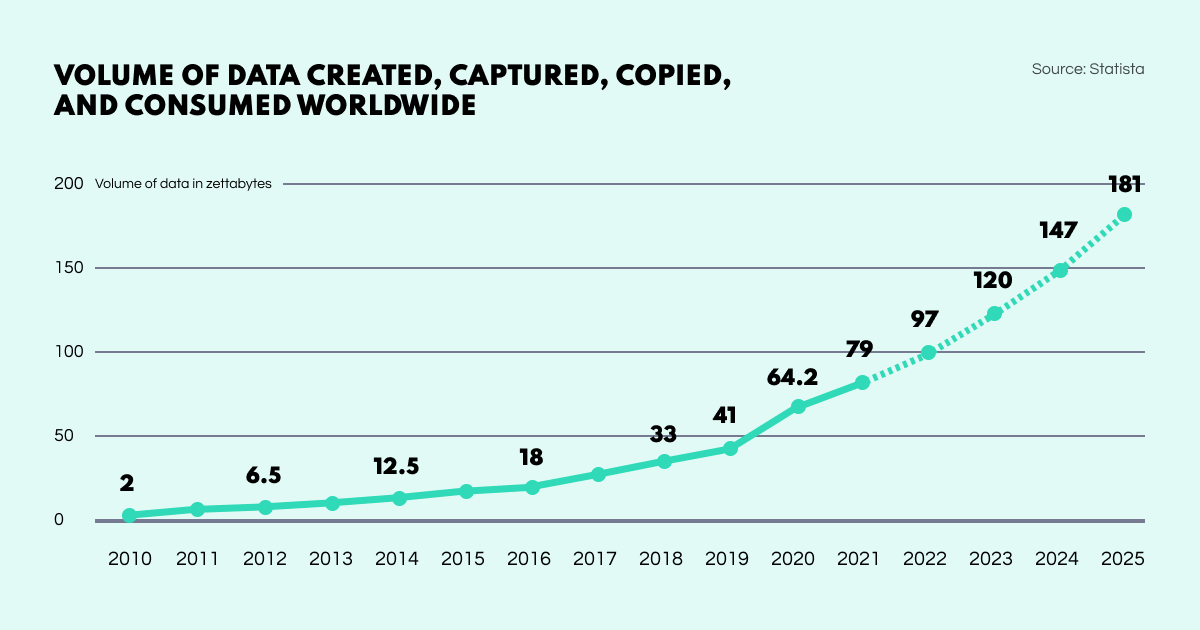
Data Overload. Currently weighing in at 79 zettabytes, the datasphere is gargantuan. Confronted with such amounts of raw data along with demanding time constraints, OSINT analysts have their work cut out. By gaining access to an array of powerful search functions, users have far greater control over the way information is extracted: relevant data can be zeroed in on, while superfluous material can be filtered away. This makes the gathering process quicker, easier, and more focused, resulting in greater overall productivity.
The datasphere volume is set to exceed 180 zettabytes by 2025
Artificial Intelligence. AI technologies seem to be cropping up everywhere these days. But in OSINT work, they are often essential, with machine learning and natural language processing taking care of many aspects of data retrieval, organization and processing. AI models can quickly sort diverse, nebulous data into coherent, workable material. This means investigators can devote more energy and headspace to making effective decisions in driving the investigation forward.
Covert Work. Blown cover can easily result in a blown case. Most surveillance depends on the illusion that it isn’t going on. Many websites use tracking techniques, and social media platforms require registration to view profiles. For analysts required to conduct covert investigations, such approaches are simply not an option. With their anonymized search algorithms, open-source intelligence tools are not only able to disclose any type of open data required, they can do so without alerting the subject to the fact that they are under observation.
💡
With the open-source intelligence industry dramatically expanding, there are a great many solutions out there, each with their own specialization and functionality. Social Links’ current line up consists of two products:
SL Professional. Our flagship all-in-one OSINT solution for conducting in-depth investigations across social media, blockchains, messengers, and the Dark Web. This professional bundle provides 1000+ advanced extraction and analysis methods for 500+ open data sources and 1.3 billion identities.
SL Private Platform. Our enterprise-grade on-premise OSINT solution with customization options, private data storage, and our widest range of search methods. Conceived for use by major intelligence organizations, this unique product provides a comprehensive suite of tools for all OSINT applications.
Any questions? We’d be happy to give you a guided demonstration of our OSINT tools and show how they can transform your workflows. Simply follow the link, fill out the short contact form and we’ll be in touch promptly to arrange a call.